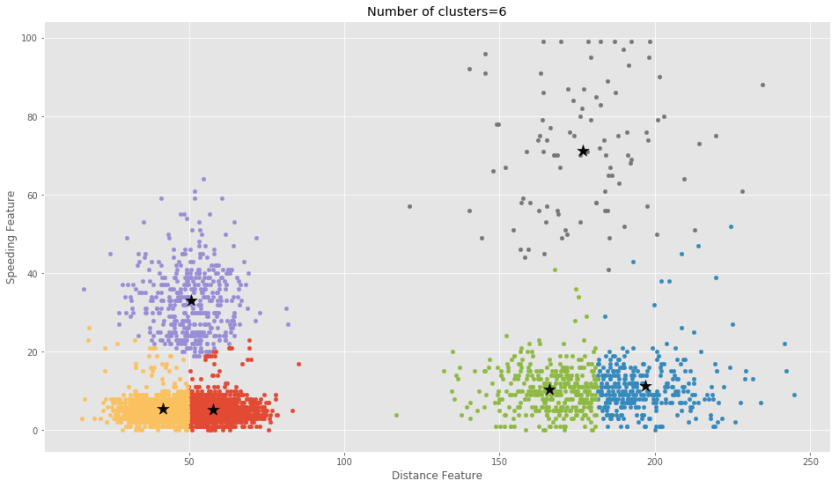
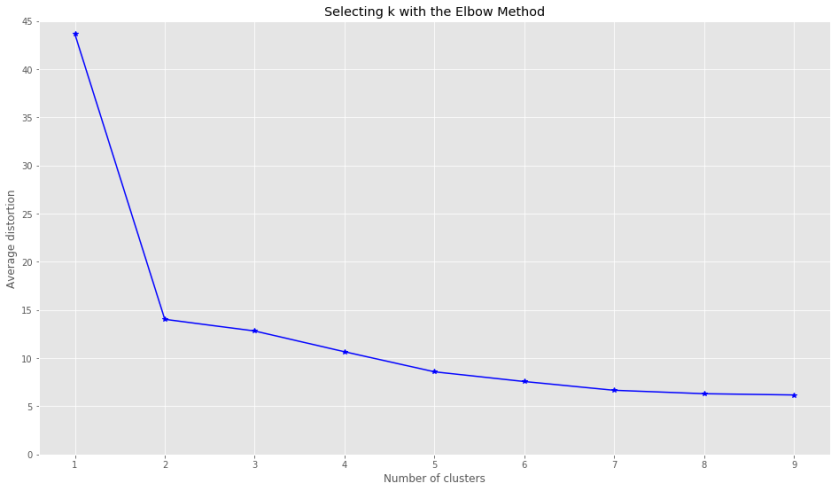
Have you ever wonder how Amazon determines “customers who bought this item also bought…” info? They just simply implemented a recommender system. Netflix also uses similar algorithms to determine what to recommend to watch based on user’s data trail in the system. Now if you are interested in knowing more about how a recommender system can be implemented in a simple example, here we go…
First, we need a rider for our huge user data(a.k.a. Big Data), that is Apache Mahout! Mahout is an open source Machine Learning Library that contains algorithms for clustering, classification and recommendation. It is written in Java and is linearly scalable with data. It supports batch processing of sequential data where data size is irrelevant. Most importantly, it can be executed in memory or on a distributed mode.
Recently, we see Mahout shifting from Hadoop/HDFS towards Spark as it provides better support for iterative machine learning algorithms using the in-memory approach.
Now let us dive more deeply into what recommendation algorithm and techniques we can use.
Recommendation algorithm that is frequently used is called Collaborative Filtering.
Collaborative Filtering
Collaborative filtering technique uses historical data on user behavior, such as clicks, views, and purchases, to provide better recommendations.
Item-based recommender – similar users from a given neighborhood are identified and item recommendations are given based on what similar users already bought or viewed, which a particular user did not buy or view yet.
User-based recommender – An item-based recommender measures the similarities between different items and picks the top k closest (in similarity) items to a given item in order to arrive at a rating prediction or recommendation for a given user for a given item.
Matrix factorization-based recommender– new items and new users tend to lack sufficient historical data to predict good recommendations. This is known as the cold start problem ,rating can be induced by a mathematical techniques.
There are different types of similarity measures available to use to build recommenders. Here are some of the most popular ones:
- PearsonCorrelationSimilarity: measure to find similarity between two users.
- EuclideanDistanceSimilarity: This measures the Euclidean distance between two users or items as dimensions and preference values given will be values along those dimensions. EuclideanDistanceSimilarity will not work if you have not given preference values.
- TanimotoCoefficientSimilarity: This is applicable if preference values consist of binary responses (true and false). TanimotoCoefficientSimilarity is the number of similar items two users bought or the total number of items they bought.
- LogLikelihoodSimilarity: This is a measure based on likelihood ratios. The number of co-occurring events, in this context, the number of times either users or items that occurred together and the number of times either users or items that do not occur together, are considered for evaluating similarity.
- SpearmanCorrelationSimilarity: the relative rankings of preference values are compared instead of preference values.
- UncenteredCosineSimilarity: This is an implementation of cosine similarity. The angle between two preference vectors is considered for calculation.
We should always consider the percentage of error in order to measure the quality of our recommendations. We can do it by evaluating how closely the estimated preferences match the actual preferences of a user. How it is done basically is that we split the data set into two portions – training data set and testing data set.
The training dataset is used to create the model, and evaluation is done based on the test dataset, and we can calculate the evaluation percentage according to IR-based Evaluation method as follows:

Precision is the proportion of top recommendation retrieved to the total of the recommendation.
Recall is the recommended items retrieved divided by total of recommendations available.
The F1 score can be interpreted as a weighted average of the precision and recall, where an F1 score reaches its best value at 1 and worst score at 0.
In simple words, The precision is the proportion of recommendations that are good recommendations, and recall is the proportion of good recommendations that appear in top recommendations.
Recommending items to a user:
Here is the content of the input file we used for our example.

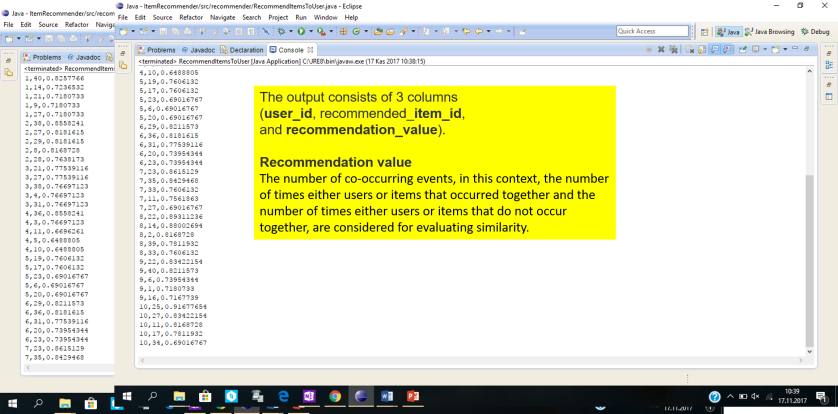
I wrote this recommender in Java using Mahout libraries. It could also be implemented in Python. In this example, we recommend 5 items to first 10 users using LogLikelihoodSimilarity measure in Mahout.

And here is the output after running the code. You will see 5 recommended items per user in the following format.
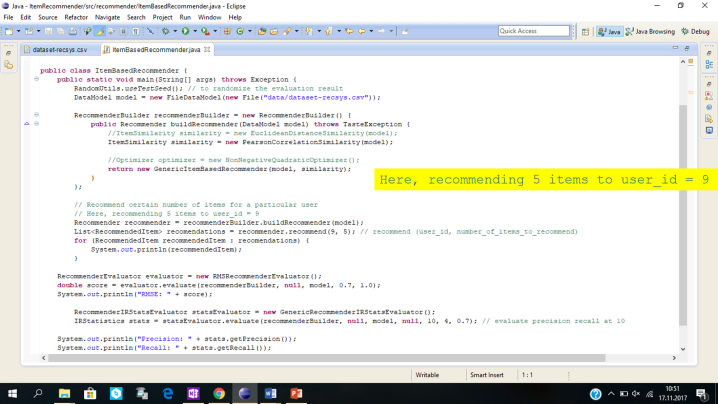
Implementing Item-based Recommender:
An item-based recommender measures the similarities between different items and picks the top k closest (in similarity) items to a given item in order to arrive at a rating prediction or recommendation for a given user for a given item.
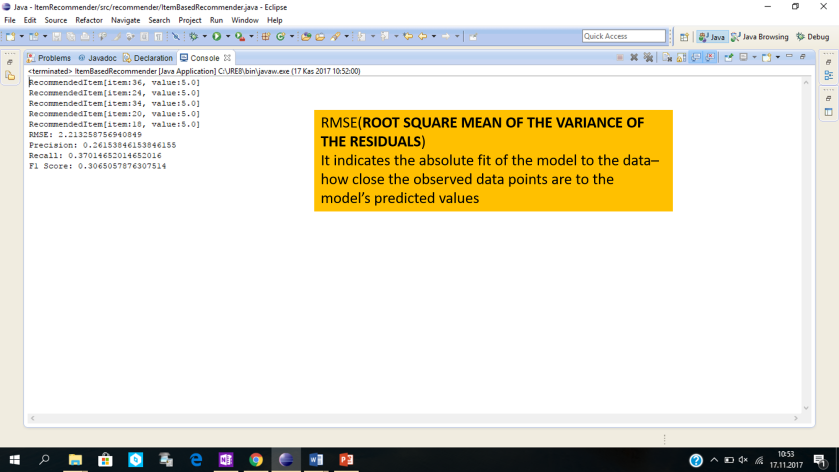
The evaluation is done for metrics Root Mean Square Error (RMSE), Precision, Recall, and F1 Score. Certain number of items are also recommended for a particular user.
Here is the output we get.
And here is the code I implemented for User-based recommender and the output.


If you would like to try it yourself, here is a good tutorial that you can benefit on Youtube.